平均値、中央値、最瀕値、分散、偏差、誤差、相関関係、相関係数、回帰、回帰式、最小二乗法、共分散、検定、有意などの言葉が意味するものを理解する事。表の書き方、図の描き方にも留意。正規分布やポアソン分布はどの様なもので見られるか。棒グラフ、折線グラフ、散布図をどの様な時に描いたら良いのか、Histogramと棒グラフは何が違うのか、x軸とy軸に何を選ぶべきか、独立変数と従属変数の区別、dataに何等かの変換処理を施した方が良いのはどんな時か、変換にはどんな物があるか、等など。ある事に付いて何かを言うためには、様々な手続が必要である。
統計処理
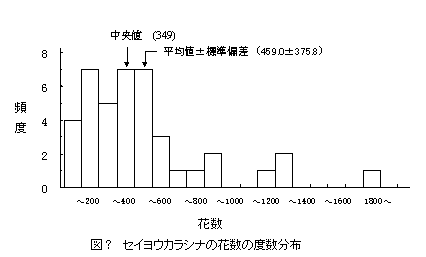
1) histogram : ある形質の度数分布をみる為の図である。測定値の最大、最小を知った上で、適当な区間幅に区切る必要がある。
(例 個体数: 3 4 7 6 6 4 2 0 1 1
-----------------------------------------------
長 さ:0-1 -2 -3 -4 -5 -6 -7 -8 -9 10- [mm]
の様に調べた後で、横軸に測定値、縦軸に個体数を示す。
[区間幅の取り方で、分かり易くも分かり難くもなるので注意。]
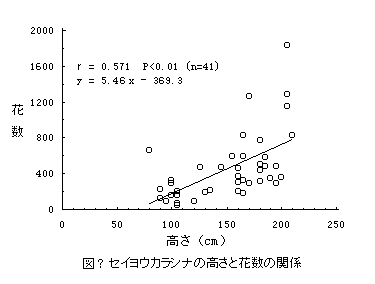
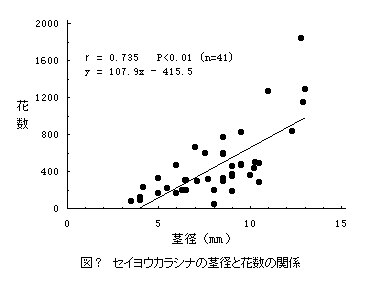
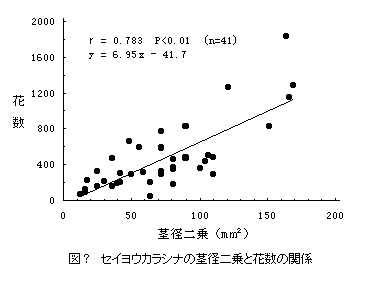
2) 散布図(scattergram):二形質の測定値を一枚の図上に描くことで、両者の関係をたやすく捉えられる。(例えば、横軸に茎の直径、縦軸に花の数をとり、各個体の計測値を図に打っていく。)
3) 中央値(median)と最頻値(mode)
中央値:標本を値の大小の順に並べた時、中央の物が示す値
最頻値:最も頻出する値
これら2つの値は、上記 histogam を描く際に求まっている筈である。
4) * 平均と標準偏差(mean, standard deviation)
標本数 =N 総和 Sx=∑x ・平均 xm=Sx/N
偏差平方和 Sx2=∑(x-xm)2=∑x2-xm∑x =∑x2-N・xm・xm
分散 S2=Sx2/(N-1) ・標準偏差 SD=√S2
・分散は偏差平方和を標本数(N-1)で割ったもの、偏差は分散の平方根である。
これらは、dataの散らばり具合いを表わす指標となる。平均と偏差は、一緒に使われる事が多い(mean ± SD のように)。
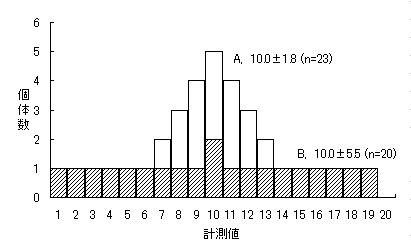
ある形質に付いて、調べた二群が同じ平均値を示しても、dataの散らばり具合が同じとは限らない。例えば、下図の白棒で示されたA群と斜線で示されたB群の平均値は共に10.0であるが、dataの散らばりを表す指標である標準偏差値は、それぞれ 1.8(標本数 23)と 5.5(標本数 20)になる。
5) * 相関係数(correlation coefficient)と回帰直線(regression line)
偏差積和 Sxy=∑(x-xm)(y-ym) =∑(xy-x・ym-xm・y+xm・ym)
=∑xy-ym∑x-xm∑y+∑xm・ym =∑xy-ym・N・xm-xm・N・ym+N・xm・ym
=∑xy-N・xm・ym
共分散(Covariance) Cxy=Sxy/(N-1) ・相関係数 r=Sxy/√(Sx2・Sy2)
回帰係数(yのxへの) b=Sxy/Sx2 =r・√Sy2/√Sx2 =r・SDy/SDx
・回帰直線 (y-ym)=b・(x-xm) → y=b・x+(ym-b・xm)
・相関係数は(-1.0~ 1.0)の値をとる。0 は、比べた両形質が全く独立であること。絶対値 1は、完全な直線関係があることを示す。相関係数は必ず求まるが、有意な相関か否かについては、別に統計量 F=(n-2)・r2/(1-r2)を出して判定する。F は、自由度対[1, n-2]のF-分布に従って分布するので、統計の本に載っているF-分布表の対応する数値と比較する。計算値が表値より大きければ有意である。ここでは、何と何の関係を見るのか、その事に意味があるのか等を考えねばならない。また、計測値に何らかの操作を加えた方が、よい相関が得られる場合がある。その時には、その理由を考える。・回帰直線は、通常は最小2乗法により求める。これは、各dataの点と直線との距離の2乗の総和が最小になるような直線である。
こういう事がある程度分かっていれば、偶然の揺らぎに惑わされてとんでもない結論を導く事も減るだろう。 統計処理に関する考え方や方法などを身に付けるために、参考になりそうな本を何冊か挙げておく。